들어가며
평소 즐겨보는 에디의 기술블로그에서 캐싱이야기를 보게 되어 스프링을 이용하여 캐싱하는 방법에 대해 기술합니다.
캐싱이란? 참고글
캐싱은 자주 사용되는 데이터를 원본 데이터 소스보다 빠르게 액세스 할 수 있는 임시 위치에 저장하는 기술입니다. 이렇게 하면 데이터를 검색하는 데 걸리는 시간을 줄여 애플리케이션 및 웹사이트의 성능을 크게 향상할 수 있습니다.
캐싱을 사용하면 다음과 같은 몇 가지 이점이 있습니다.
- 향상된 성능: 캐시된 데이터는 디스크 드라이브에 저장된 데이터보다 훨씬 빠르게 액세스 할 수 있으므로 애플리케이션 및 웹사이트 성능이 크게 향상될 수 있습니다.
- 비용 절감: 데이터베이스 및 기타 백엔드 시스템의 부하를 줄임으로써 캐싱은 비용을 절감하는 데 도움이 될 수 있습니다.
- 확장성 향상: 캐시된 데이터는 여러 서버에 분산될 수 있으므로 애플리케이션 및 웹사이트의 확장성을 향상하는 데 도움이 될 수 있습니다.
하지만 고려해야 할 몇 가지 중요한 사항도 있습니다.
- 데이터 일관성: 캐시된 데이터가 원본 데이터 소스의 데이터와 일관되도록 하는 것이 중요합니다.
- 캐시 무효화: 원본 데이터 소스의 데이터가 변경되면 캐시 된 데이터를 무효화하여 사용자가 최신 정보를 액세스 할 수 있도록 해야 합니다.
- 보안: 캐시된 데이터는 무단 액세스를 방지하기 위해 보호되어야 합니다.
1. 스프링에서 기본으로 제공하는 캐시 구현체
ConcurrentHashMap
스프링에서 간단하게 캐싱을 제공하는 역할을 하는 구현체입니다. 아래와 같이 빈을 선언할 수도 있지만 스프링부트를 사용하면 `CacheManager`를 자동으로 빈으로 등록하기 때문에 `@EnableCaching`만 선언해 주시면 됩니다.
@Configuration
@EnableCaching
public class CachingConfig {
@Bean
public CacheManager cacheManager() {
return new ConcurrentMapCacheManager("members");
}
}
CacheName 커스텀
`ConcurrentMapCacheManager`를 빈으로 사용할 수 있게 되었다면 그 내부에 캐시네임을 설정해 네임스페이스처럼 캐시를 사용할 수 있습니다.
@Component
public class SimpleCacheCustomizer implements CacheManagerCustomizer<ConcurrentMapCacheManager> {
@Override
public void customize(ConcurrentMapCacheManager cacheManager) {
cacheManager.setCacheNames(List.of("members", "pets"));
}
}예를 들어 위와 같이 캐시네임을 설정하였다면, 아래 그림과 같이 두 개의 네임스페이스(캐시)가 생기고 각각은 Map형태로 Key와 Value를 가지게 됩니다.

@Cacheable
// service
@Service
public class MemberService {
private final MemberRepository memberRepository;
public MemberService(MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
@Cacheable("members")
public List<Member> findAll() {
return memberRepository.findAll();
}
@Cacheable("members")
public List<Member> findAll(Integer age) {
return memberRepository.findAllByAgeGreaterThanEqual(age);
}
}
// repository
public interface MemberRepository extends JpaRepository<Member, Long> {
List<Member> findAllByAgeGreaterThanEqual(Integer age);
}테스트할 서비스와 레퍼지토리 클래스를 생성합니다.
테스트는 통합테스트를 진행했으며 Repository를 MockBean으로 선언하였습니다.
파라미터가 없는 메서드를 캐싱할 때
통과하는 테스트 코드는 아래와 같습니다.
@Test
void 파라미터가_없는_메서드_캐싱하는_경우() {
ArrayList<Member> list = createMembers();
when(memberRepository.findAll()).thenReturn(list);
memberService.findAll(); // 최초 호출 시 캐싱
memberService.findAll(); // 재호출 시 캐싱된 데이터를 바로 응답하고 내부로직을 진행하지 않음
verify(memberRepository, times(1)).findAll();
}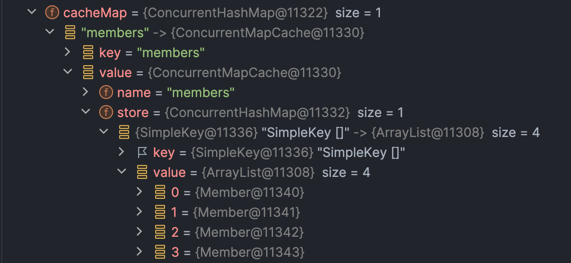
디버깅을 하게 되면 members라는 캐시가 생성되었고 내부에 “SimpleKey[]” key에 캐싱된 데이터가 value로 존재하는 걸 볼 수 있습니다.
파라미터가 있는 메서드를 캐싱할 때
@Test
void 파라미터가_있는_메서드_캐싱하는_경우() {
ArrayList<Member> list = createMembers();
int startAge = 10;
when(memberRepository.findAllByAgeGreaterThanEqual(startAge)).thenReturn(list);
memberService.findAll(startAge);
memberService.findAll(startAge);
verify(memberRepository, times(1)).findAllByAgeGreaterThanEqual(any());
}
디버깅을 하게되면 key는 파라미터로 들어온 startAge인 것을 볼 수 있습니다. `@Cacheable`은 기본적으로 메서드로 들어온 파라미터를 key로 사용합니다. key를 커스텀 하고 싶을 땐 KeyGenerator를 이용할 수 있습니다.
이 외에도 캐시된 데이터를 지우는 `@CacheEvict`, 새롭게 데이터를 밀어 넣는 `@CachePut` 애너테이션 등이 있습니다.
참고로 `@Cacheable`은 캐시 읽기 전략 중 look-aside 방식입니다.
2. spring-data-redis에서 제공하는 CacheManager
RedisCacheManager
의존성 추가
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
Configuration bean 등록
@Bean
public RedisCacheConfiguration redisCacheConfiguration() {
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofMinutes(1))
.disableCachingNullValues()
.serializeValuesWith(RedisSerializationContext
.SerializationPair
.fromSerializer(new GenericJackson2JsonRedisSerializer()));
}spring-data-redis 의존성을 추가하게 되면 `CacheManager`의 구현체는 자동으로 `RedisCacheManager`가 선택됩니다.이 전에 Redis 서버를 먼저 띄워주셔야 합니다.
또한 설정을 추가로 등록함으로써 오브젝트 형태를 시리얼라이즈 할 수 있는 `GenericJackson2JsonRedisSerializer`를 설정해 줍니다. 그렇지 않으면 객체를 직렬화할 수 없다는 에러를 보실 수 있습니다.


`RedisCacheManager`가 캐시매니저로 등록된 것을 보실 수 있습니다. 또한 파라미터 존재하는 메서드를 테스트할 경우 레디스에 정상 저장되는 것을 보실 수 있습니다.
Multiple CacheMap (캐시네임별로 다른 설정을 주고 싶을 때)
캐시네임별로 TTL을 다르게 주고 싶거나 설정을 다르게 하고 싶은 경우에는 아래와 같이 추가설정을 할 수 있습니다.
@Configuration
@EnableCaching
public class CachingConfig {
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory) {
return RedisCacheManager.builder(connectionFactory)
.cacheDefaults(getDefaultCacheConfig())
.withInitialCacheConfigurations(
Map.of("one_minute", oneMinuteCacheConfiguration(),
"five_minute", fiveMinuteCacheConfiguration())
).build();
}
private RedisCacheConfiguration getDefaultCacheConfig() {
return RedisCacheConfiguration.defaultCacheConfig()
.disableCachingNullValues()
.serializeValuesWith(RedisSerializationContext
.SerializationPair
.fromSerializer(new GenericJackson2JsonRedisSerializer()));
}
private RedisCacheConfiguration oneMinuteCacheConfiguration() {
return getDefaultCacheConfig().entryTtl(Duration.ofMinutes(1));
}
private RedisCacheConfiguration fiveMinuteCacheConfiguration() {
return getDefaultCacheConfig().entryTtl(Duration.ofMinutes(5));
}
}이후 캐시네임을 `@Cacheable("one_minute")` 로 설정하면 1분의 TTL이 적용됩니다. `@Cacheable("other")`같이 따로 설정되어 있지 않은 캐시네임을 사용하면, 기본설정 값이 적용됩니다.
3. Multiple Redis Server
서로 다른 레디스 서버를 따로 이용하고 싶다면?
여러 레디스 서버를 각각 세션클러스터링, 캐싱용도 등으로 사용하고 싶을 땐 커넥션을 분리해서 사용할 수 있습니다.
public class CachingConfig {
@Bean
@Primary
public LettuceConnectionFactory defaultRedisConnectionFactory() {
return new LettuceConnectionFactory(new RedisStandaloneConfiguration("localhost", 63791));
}
@Bean
@Qualifier("cacheConnectionFactory")
public LettuceConnectionFactory cacheConnectionFactory() {
return new LettuceConnectionFactory(new RedisStandaloneConfiguration("localhost", 63792));
}
@Bean
public RedisCacheManager cacheManager(@Qualifier("cacheConnectionFactory") RedisConnectionFactory connectionFactory) {
return RedisCacheManager.builder(connectionFactory)
.cacheDefaults(getDefaultCacheConfig())
.withInitialCacheConfigurations(
Map.of("one_minute", oneMinuteCacheConfiguration(),
"five_minute", fiveMinuteCacheConfiguration())
).build();
}
// .. default, one_minute_config,..
}
위와 같이 설정을 하게 되면 캐시용도로 캐시매니저를 찾을 땐 커스텀한 커넥션을 이용한 `CacheManager`를 사용해 63792 레디스를 이용할 것입니다. 반대로 다른 용도로 (ex: `@RedisHash`)사용하게 되면 `@Primary`를 사용한 63791 레디스 서버를 이용할 것입니다.
4. 마치며
지금까지
- 스프링에서 제공하는 기본 캐시 구현체
- 레디스를 이용하여 캐싱하는 방법
- 레디스의 캐시네임별 설정을 다르게 하는 법
- 서로 다른 레디스 서버를 함께 사용하는 법
을 알아보았습니다. 읽어주셔서 감사합니다.
look-aside 전략
- 가장 일반적
- 앱은 데이터를 찾을 때 캐시를 먼저 찾음
- 찾는 데이터가 캐시에 없다면 데이터베이스에 찾고 레디스에 저장함
- 찾는 데이터가 없을 때에만 쓰기 작업이 일어나기 때문에 Lazy loading이라고도 함
- 레디스 장애가 발생하면 레디스에 붙던 커넥션이 모두 디비로 붙기 때문에 부하가 몰릴 수 있음
- 캐시를 새로 구축하거나 데이터베이스에만 데이터를 추가한다면 초반에 캐시미스가 많이 발생해 성능에 저하가 발생할 수 있음
- 이럴 때는 캐시에 데이터를 밀어 넣는 캐시워밍(Cache Warming)을 진행할 수 있음
Reference
https://docs.spring.io/spring-data/redis/reference/redis/redis-cache.html
https://www.baeldung.com/spring-cache-tutorial
https://www.youtube.com/watch?v=92NizoBL4uA&ab_channel=NHNCloud
'Spring' 카테고리의 다른 글
| 쓰기, 읽기 전용 Multiple DataSource 설정하기 (1) | 2024.06.04 |
|---|---|
| Use Redis to Session Storage (0) | 2024.05.19 |
| IP 기반 API 호출 횟수 제한 (2) | 2024.05.17 |
| 스프링에서 관리하는 세션의 생성구조와 키의 암호화 (0) | 2024.05.16 |
| 분산 시스템 환경에서 Scheduler 단일 동작시키기 (0) | 2024.04.24 |