1. 문제 관측: 푸시 알림 클릭 후 1분간의 상품 목록 로딩
어느 날, MD 팀에서 발송한 이벤트 푸시 알림을 확인하던 중 이상한 현상을 발견했다.
알림을 눌러 앱을 실행하자, 상품 목록이 로딩되는 데 약 1분 가까이 걸렸다.
보통 해당 페이지는 수백 개의 상품을 로드하더라도 1초 내외로 표시되는 것이 정상이다.
그런데 이번에는 앱이 멈춘 듯한 상태로 머물러 있었고, 사용자가 중간에 이탈할 만한 수준의 지연이었다.
이벤트 페이지로 랜딩하는 푸시 알림이라는 점에서 문제의 영향 범위는 단순한 UI 불편을 넘어섰다.
마케팅 효과 측면에서도 심각한 손실로 이어질 가능성이 높았다.
단순히 일시적인 네트워크 지연이 아니라, 시스템적 병목이 의심되는 상황이었다.
운영 환경 로그를 함께 살펴본 결과, 앱 자체나 네
트워크보다는 서버 응답이 비정상적으로 지연되는 패턴이 공통적으로 나타났다.
2. 문제 원인 추적: 느려진 쿼리와 RDS CPU 100%
지연 현상이 서버 단에서 발생한다는 점을 확인한 뒤, 우선 데이터독 모니터링 지표를 살펴보았다.
API의 p95 응답 시간이 약 1분까지 상승해 있었다.

이 시점에서 RDS 모니터링 지표를 함께 확인하자, CPU 사용률이 100% 찍는 모습이 나타났다.
특정 시점 이후 급격히 부하가 증가한 패턴이 뚜렷했다.
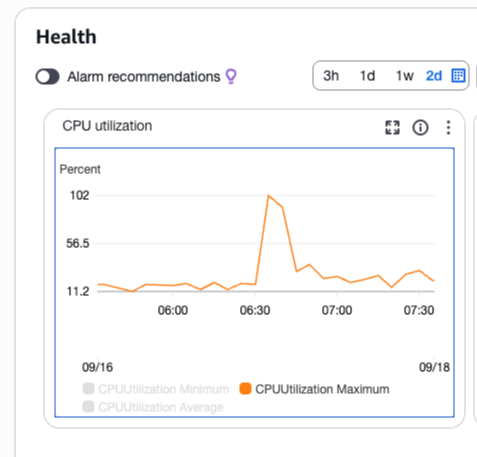
슬로우 쿼리 로그를 추적한 결과, 원인은 상품 재고를 조회하는 쿼리였다.
이 쿼리는 이벤트 페이지뿐 아니라 여러 상품 페이지에서도 공통으로 사용되고 있었기 때문에,
한 번 병목이 생기면 전체 트래픽에 영향을 주는 구조였습니다.
결국, 문제의 핵심은 재고 조회 쿼리의 비효율적인 처리 방식이라는 결론에 도달했다.
3. 원인 분석: JSON 컬럼 기반 재고 계산 로직의 비효율성
문제가 된 쿼리는 상품 재고를 계산하는 로직이었다.
재고 데이터는 별도의 테이블이 아닌, 상품 옵션 정보 내부의 JSON 컬럼에 함께 저장되어 있었다.
즉, 각 옵션별 재고 수량이 JSON 배열 형태로 기록되어 있었고,
조회 시에는 이 JSON 데이터를 파싱해 합산하는 방식이었다.
이 구조는 단순 조회에서는 큰 문제가 없었지만,
옵션 수가 많은 상품의 재고를 한 번에 계산해야 하는 상황에서는 파싱 연산 비용이 크게 증가했다.
게다가 해당 컬럼은 일반 인덱스를 직접 걸 수 없었고,
JSON 경로 기반 인덱스나 생성 컬럼을 별도로 구성하지 않은 상태였다.
결과적으로 쿼리가 매번 JSON 필드를 전부 읽어 들여야 했고,
상품 옵션 수가 많을수록 사실상 대량 스캔에 가까운 동작이 발생했다.
이 문제는 단순 쿼리 튜닝이나 인덱스 추가로 해결하기 어려웠다.
데이터 모델이 조회 효율성보다는 저장 편의성 위주로 설계되어 있었기 때문이다.
즉, 구조 자체가 읽기 작업에 비효율적인 형태였고,
DB가 재고 계산을 위해 불필요하게 많은 연산을 수행하도록 만들고 있었다.
4. 해결 시도와 결정: 캐시 vs 조회용 테이블
원인을 확인한 뒤, 우선 떠올랐던 해결책은 캐시를 두는 방식이었다.
요청이 몰리는 시점에 DB 접근을 줄일 수 있고, 가장 빠르게 적용할 수 있는 방법이었기 때문이다.
실제 트래픽 패턴을 고려했을 때도 캐시의 효과는 분명 있을 것으로 보였다.
하지만 곧바로 캐시를 적용하기에는 문제가 있었다.
재고 데이터는 이벤트 페이지뿐만 아니라 상품 상세 페이지, 검색 결과 등 다양한 곳에서 공유되고 있었다.
즉, 한 영역만 캐시를 두더라도 다른 영역에서 여전히 동일한 비효율이 반복될 가능성이 있었다.
또한 재고 정보는 주문이나 취소와 함께 자주 변경되기 때문에,
캐시를 안정적으로 유지하기 위한 동기화 비용이 추가로 발생할 수 있었다.
결국 보다 근본적인 접근이 필요하다고 판단했다.
재고가 변경될 때마다, 동일 트랜잭션 내에서 조회용 재고 테이블을 함께 갱신하도록 구조를 변경하기로 했다.
이렇게 하면 조회 시점에는 단순 SELECT 쿼리만 수행하면 되고,
복잡한 JSON 파싱 로직이 사라지기 때문에 DB 부하를 획기적으로 줄일 수 있었다.
팀장님께 구조 변경 방향을 공유했고, 검토 후 작업을 진행했다.
결과적으로 기존 로직을 유지한 채 캐시로 임시 대응하기보다,
데이터 모델 자체를 개선하는 방향으로 결정하게 되었다.
5. 결과와 회고: p95 1분 → 300ms, 그리고 구조적 개선의 의미
구조를 변경한 뒤, 가장 먼저 확인한 것은 응답 지표였다.
변경 전 1분까지 치솟던 p95 응답 시간이 약 300ms 수준으로 감소했다.
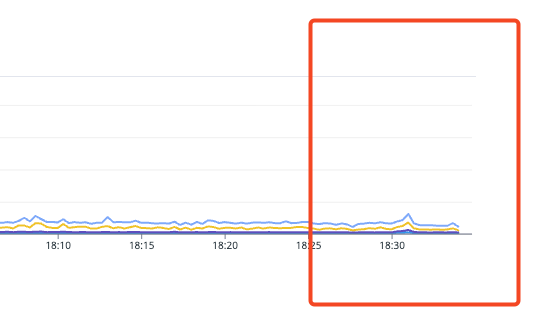
RDS CPU 사용률도 안정적으로 유지되었고, 트래픽이 집중되는 시간대에도 병목이 발생하지 않았다.
앱에서도 상품 목록이 즉시 로드되었고, 사용자 불편이 사라졌다.
결과적으로 단순한 성능 개선을 넘어,
데이터 구조가 서비스 성능에 미치는 영향을 명확히 체감할 수 있는 사례였다.
그동안 데이터 저장 구조는 상대적으로 덜 중요하게 여겨졌지만,
읽기 패턴이 많은 서비스에서는 설계 초기부터 조회 효율성을 고려해야 한다는 점을 배웠다.
또한, 캐시를 통한 임시 대응보다
근본적인 원인에 집중하는 판단이 장기적인 유지보수성에 더 도움이 된다는 점도 확인했다.
재고 로직이 단순해지면서, 이후 기능 개발이나 테스트에서도 불필요한 복잡도가 줄어들었다.
이번 경험을 통해, 문제를 “해결하는 것”보다 “왜 이런 구조가 만들어졌는지”를 이해하는 것이
더 큰 학습이 된다는 사실을 느꼈다.
결국 성능 최적화는 단순한 기술적 조정이 아니라,
데이터 모델과 시스템 설계 전반을 다시 점검하는 계기가 되어야 한다고 생각했다.
'트러블슈팅' 카테고리의 다른 글
| 발급 쿠폰 갱신 작업에서 발생한 OOM 원인: JPA 1차 캐시 이야기 (0) | 2025.10.13 |
|---|